AWS ECS vs EKS for B2B SaaS: A Decision Matrix for Cost, Operability, Security, and Platform Roadmap
2026-04-30
Start with your SaaS constraints and success targets
 Constraints shape the ECS vs EKS starting point
Constraints shape the ECS vs EKS starting point
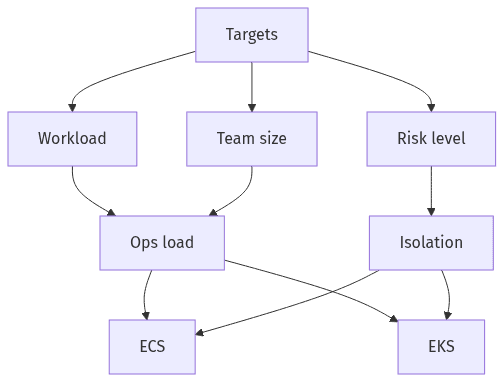
Container orchestration choices in B2B SaaS tend to age poorly when they begin with feature preference instead of operating constraints. Platform selection usually tracks the product’s current posture (MVP speed versus enterprise expectations), the stability required for retention, and the organization’s capacity for day-two operations. Explicit success targets also reduce costly reversals later, because operability patterns, security controls, and observability conventions become entrenched early. ECS and EKS both support modern SaaS delivery, but they reward different maturity profiles and different definitions of acceptable reliability.
Workload and team readiness
Workload shape and staffing limits usually decide the outcome more than theoretical capability. Lean DevOps teams often optimize for fewer moving parts and bounded day-two responsibilities, particularly during MVP-to-growth transitions. Enterprise-facing SaaS roadmaps, by contrast, tend to pull toward tighter standardization, ecosystem expectations, and reliability practices that raise the operational baseline.
Non-negotiables and acceptable risk
Non-negotiables typically cluster around tenant isolation, resilience targets, and audit evidence, with acceptable blast radius acting as the forcing function. The highest-cost ambiguity often appears when isolation requirements remain undefined until a security review or a late-stage customer negotiation. Those moments routinely turn platform tradeoffs into contractual exposure and reputational risk.
ECS vs EKS: the executive decision matrix
 Executive view: tradeoffs across five decision pillars
Executive view: tradeoffs across five decision pillars
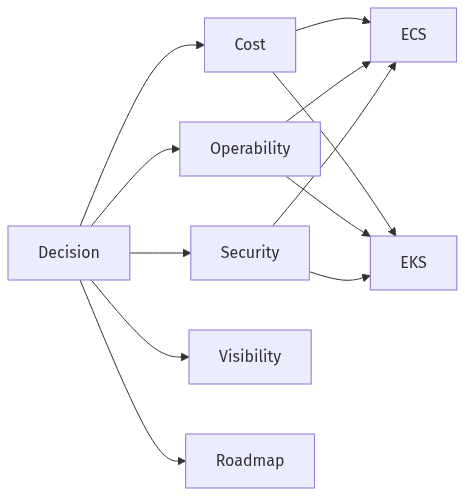
At the executive level, ECS versus EKS tends to present as a portfolio decision across cost, operability, security posture, observability consistency, and roadmap leverage, not a feature comparison. ECS usually reflects a managed-simplicity bias, while EKS reflects an ecosystem and standardization bias. Misalignment typically surfaces as hidden operational drag (when EKS arrives before the operating model can sustain it) or accumulated constraints (when ECS is stretched past its natural fit to preserve platform uniformity). A decision matrix makes the tradeoffs explicit: which are acceptable now and which are likely to become future liabilities.
When ECS is the better fit
ECS commonly fits SaaS platforms that prioritize operational simplicity, repeatable workload patterns, and delivery cadence with limited platform overhead. Smaller DevOps teams often benefit from reduced control-plane responsibility and fewer mandatory add-on choices. Predictability generally improves when requirements center on stable long-running services and routine scaling rather than broad Kubernetes ecosystem flexibility.
When EKS is the better fit
EKS commonly fits SaaS organizations that prioritize Kubernetes standardization, ecosystem compatibility, and longer-horizon platform optionality. That flexibility usually comes with higher expectations for operational discipline, including cluster lifecycle management and consistent conventions across teams. The rationale strengthens when internal platform plans depend on common primitives across environments and shared operational patterns.
Cost and total ownership: what actually drives spend
 TCO is compute plus supporting services and ops overhead
TCO is compute plus supporting services and ops overhead
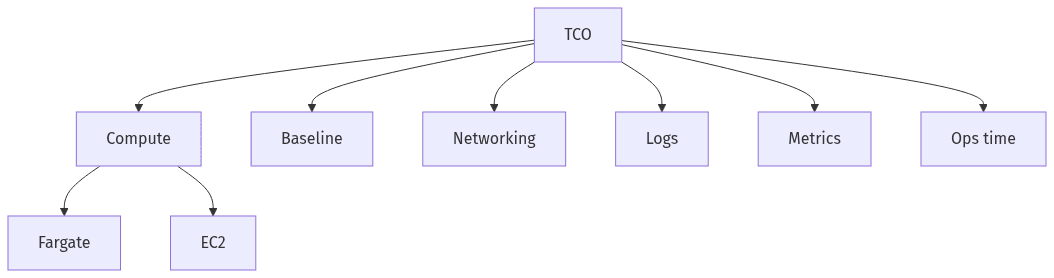
Cost discussions often collapse into compute rates, while total ownership is shaped by baseline platform charges, add-ons, and the organizational overhead required for safe operations. Both ECS and EKS can run on Fargate or EC2, but the cost profile changes once control-plane fees, integrations, and governance effort are included. Kubernetes spend often grows through ancillary costs that compound over time: networking, load balancing, logging, metrics, and operational tooling. Unit economics typically become clearer when allocation aligns to services, tenants, and environments rather than generalized account-level spend.
Biggest cost drivers to consider
Compute is visible, but supporting services often drive surprises. Fargate versus EC2 choices influence baseline spend and predictability, while EKS usually adds fixed cluster fees and ecosystem add-ons that accrue continuously. Observability retention, load balancers, data transfer, and managed integrations frequently determine whether container-platform spend stays aligned with SaaS margin assumptions.
Keeping costs predictable over time
Predictability typically correlates with governance maturity: clear ownership, consistent tagging and allocation, and shared visibility into drivers that scale with usage. Kubernetes environments often amplify variance when add-ons proliferate and standards drift between teams. FinOps discipline becomes a practical control surface, because spend patterns often mirror architectural consistency and operational accountability.
Security and audit readiness for B2B SaaS
B2B SaaS security choices increasingly follow customer scrutiny rather than internal preference, and audit readiness becomes an ongoing operating condition. Neither ECS nor EKS delivers compliance by default; both rely on shared responsibility across IAM, network boundaries, change accountability, and durable evidence. Least-privilege access, audit logging, and traceable change history typically matter as much as runtime isolation. Multi-tenant risk is particularly sensitive because cross-tenant exposure can turn a single defect into a material incident. Platform choice influences how consistently controls are enforced, monitored, and evidenced over time.
Tenant separation and limiting impact
Tenant isolation typically exists on a spectrum, from shared workloads with logical boundaries to stronger separation intended to reduce blast radius. The executive question usually centers on cross-tenant impact tolerance and the reputational cost of misconfiguration. Both ECS and EKS can support isolation goals, but the policy surface and operational overhead differ.
Audit-friendly operating habits
Audit readiness usually depends on operating habits: access traceability, change records, and clear accountability for production actions. Compliance pressure often exposes gaps in logging coverage and privilege management before it highlights missing platform features. The most durable posture treats SOC 2 and ISO 27001 as evidence-producing operating practices rather than platform checkboxes.
Make it real: a short evaluation sprint and decision
Container platform decisions tend to improve when assumptions are tested against observed behavior rather than debated in the abstract. A short evaluation sprint can surface real constraints: deployment friction, scaling behavior, visibility consistency, and cost variability under representative load patterns. The most useful outcome is typically a defensible go/no-go decision tied to observable KPIs and acknowledged failure cases, rather than a theoretical “best practice” selection. Migration risk also becomes easier to manage when the roadmap treats ECS and EKS as staged options rather than ideological commitments, especially where networking and IAM assumptions drive rework.
What to validate and how to measure
Validation typically centers on delivery velocity signals, operational noise, observability completeness across logs/metrics/traces, and early clarity on cost allocation. SLO alignment serves as a practical yardstick, because reliability targets translate into monitoring rigor and on-call load. Comparisons are usually most informative where they reveal which failure modes appear first and how quickly root cause becomes observable.
Decision triggers and next-step roadmap
Decision triggers commonly come from standardization pressure, heightened compliance expectations, and cost-governance needs rather than raw scale alone. ECS-to-EKS shifts often correlate with ecosystem requirements and uniformity goals, while remaining on ECS often correlates with stable service patterns and constrained staffing. Networking and IAM assumptions frequently become early breaking points, because they affect isolation, auditability, and day-two operability simultaneously.


