
Alex Fesak
CEO
Reducing SaaS Incident MTTR with an Event-Driven Observability Platform on AWS: Reference Architecture + Implementation Backlog
2026-05-21
Set MTTR goals and clear ownership
 Goals, ownership, and escalation reduce response ambiguity.
Goals, ownership, and escalation reduce response ambiguity.
MTTR remains elevated in B2B SaaS environments when incident response operates without shared targets and explicit accountability across microservices, tenant accounts, and on-call rotations. Executive alignment on what “good” looks like typically shifts observability discussions away from tool selection and toward reliability outcomes. When goals, ownership, and escalation expectations stay implicit, alert streams drift into ambiguity, triage slows, and responders lose confidence in signals. In AWS-native stacks, ambiguity often compounds as workloads spread across AWS Organizations, where fragmented visibility and unclear responsibility can turn routine degradations into extended outages.
Baseline and target KPIs
MTTR, time-to-detect, and time-to-engage often distinguish structured incident response from ad hoc troubleshooting. Measures such as paging accuracy, alert volume per service, and the percentage of alerts mapped to an owning service tend to predict MTTR more reliably than raw telemetry volume. Reliability targets increasingly align with SLO and error-budget thinking rather than assumptions that “more monitoring” is inherently better.
Service ownership mapping
Ownership gaps commonly surface as alerts routed to shared channels, oversized on-call rotations, or escalation paths that depend on tribal knowledge. A consistent service taxonomy—service name, environment, severity, and owning team—often forms the backbone for correlation and operational accountability. Without that mapping, centralized telemetry can still produce distributed confusion during incidents.
Unify signals and route alerts more effectively
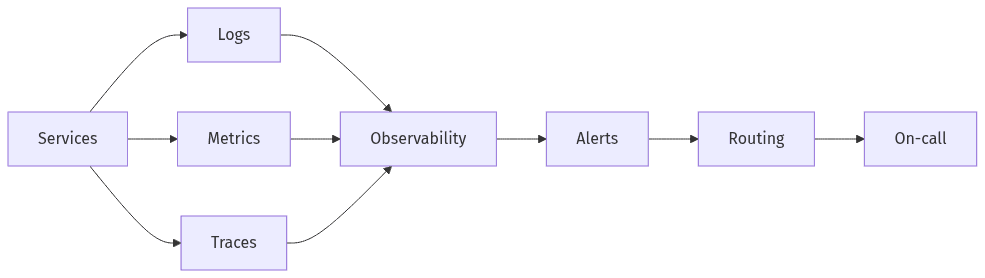 Unified signals enable faster diagnosis and cleaner alert routing.
Unified signals enable faster diagnosis and cleaner alert routing.
Faster recovery correlates with the ability to connect logs, metrics, and traces into a single investigative narrative, particularly in microservice-heavy SaaS systems with frequent deployments. AWS-native observability commonly relies on CloudWatch for logs and alarms, with distributed tracing via AWS X-Ray or ADOT to preserve trace context across services. Alerting mechanics matter as much as visibility: the same alarm can accelerate response or create churn depending on routing, ownership metadata, and deduplication. These differences typically show up in on-call load and MTTR movement.
Unified visibility across services
Fragmented signals force responders to jump between dashboards, accounts, and tools, extending triage time and increasing reliance on inference. A unified model spanning CloudWatch Logs, Metrics, and traces reduces context switching and makes correlation more immediate. ADOT often appears in AWS-native strategies because vendor-neutral telemetry reduces lock-in pressure while standardizing trace context.
Smarter alert routing
Alert routing quality often determines whether on-call time is spent on recovery or on coordination and re-triage. EventBridge and SNS patterns commonly support event-driven distribution where alert metadata, ownership tags, and severity influence who is paged and how quickly. Lightweight automation hooks, including Lambda-based enrichment, can reduce misroutes and shorten time-to-engage.
Centralize across AWS accounts safely
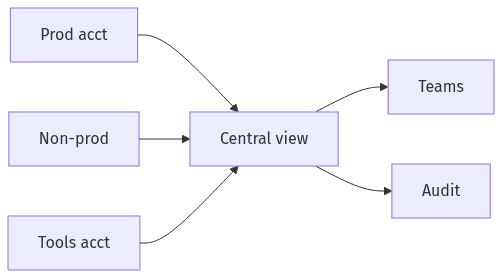 Central view with strict boundaries across environments.
Central view with strict boundaries across environments.
Multi-account architectures consistently create tension between centralized visibility and overbroad access to production telemetry. In SaaS environments using AWS Organizations, centralized observability can speed cross-service diagnosis, but it also concentrates sensitive operational data such as customer-impact indicators, identifiers, and security-adjacent logs. Executive scrutiny typically increases when teams need shared investigation across prod and non-prod, because the access model can expand blast radius if roles, policies, and boundaries are loosely defined. The credibility of an AWS-native observability platform often rests on security posture and auditability as much as dashboard coverage.
Access boundaries between accounts
Least-privilege expectations often collide with convenience when centralized log and trace access spans multiple environments. Segmentation between prod and non-prod commonly becomes a primary boundary, alongside team-scoped visibility that limits who can view or query sensitive telemetry. Cross-account patterns support centralization, but misconfiguration risk rises when access boundaries are not well defined.
Accountability and visibility
Regulated expectations and enterprise customer scrutiny often raise the bar for traceable access to observability data. Investigator audit trails, including CloudTrail-backed records of who queried what and when, typically function as a control plane for trust. Without auditable query and access history, centralized observability can introduce governance gaps even when incident outcomes improve.
Cut alert noise and control observability costs
Alert fatigue remains a recurring driver of slow incident response because noisy paging conditions teams to distrust alerts and delay engagement. Observability spend can also become volatile as microservices scale, deployment frequency increases, and telemetry cardinality rises. AWS-native platforms expose these tradeoffs through CloudWatch ingestion, retention, custom metrics, and tracing volume. Executive outcomes usually depend on the balance: fewer, higher-confidence pages and a cost model that stays predictable as usage grows. Cost guardrails and alert quality tend to reinforce each other when higher-signal monitoring reduces wasted investigation and response churn.
Improve alert quality
Noisy alert streams often come from thresholds that do not track customer impact, duplicated alarms across layers, or severity definitions that are inconsistently applied. The downstream effect is paging overload and slower triage even when telemetry coverage is broad. An “alert contract” mindset—treating alerts as actionable conditions with clear ownership—often improves trust and paging accuracy.
Manage telemetry spend
Runaway observability costs frequently originate in verbose logging, long retention, and high-cardinality metrics that scale faster than expected. Logs, metrics, and traces have different cost drivers, which makes governance a platform concern rather than an afterthought. Budgets, retention discipline, and sampling strategies commonly serve as the main levers for sustainable spend.
Choose your approach and deliver in phases
The “AWS-native alternative to Datadog” question typically resolves into capability tradeoffs, operational overhead, and total cost over time rather than feature parity. AWS-native building blocks can align with existing identity, networking, and audit controls, while third-party platforms can reduce internal platform maintenance but introduce vendor dependence and a different cost curve. In BOFU evaluations, executives generally look for evidence that the approach connects to MTTR movement, paging accuracy, and predictable spend. A phased rollout narrative often carries weight because it signals early reliability gains without overbuilding a platform before operational outcomes are clear.
Build vs buy criteria
Comparisons usually hinge on multi-account support, correlation depth across signals, auditability, and ongoing operational ownership. Datadog-like platforms often highlight faster time-to-adoption and a unified interface, while AWS-native stacks tend to center on control, integration with IAM and CloudTrail, and cost-tuning flexibility. Risk typically concentrates around platform complexity versus vendor dependence.
90-day rollout milestones
Short-horizon milestones often focus on early MTTR movement through improved correlation, clearer on-call routing, and consolidation of the highest-value telemetry first. Follow-on milestones typically refine noise reduction, access boundaries, and cost guardrails as adoption expands across accounts and services. Executive confidence tends to increase when milestones remain tied to MTTR KPIs rather than tool deployment volume.


