
Alex Fesak
CEO
Replacing a Legacy ETL with ELT on AWS for B2B SaaS: Migration Plan for Lower Cost, Faster SLAs, and Reliable Backfills
2026-05-27
Set the baseline: what must not break and what success means
Legacy ETL replacements in B2B SaaS rarely fail due to missing features; they fail when the migration alters the implied “contract” between data producers, transformation logic, and business consumers. Executive risk concentrates on dashboard continuity, KPI comparability, and confidence in refresh SLAs as volumes climb. A workable baseline tends to look less like a technical inventory and more like an explicit agreement on which outputs are protected, who approves changes, and what tolerances define acceptable variance. That shared definition of success becomes the anchor for cost, speed, and reliability decisions throughout cutover.
List dashboards, reports, and business expectations
Production dashboards and board-level reporting set hard expectations: stable schemas, consistent metric definitions, and predictable refresh timing. A KPI registry mindset reduces ambiguity by making owners, definitions, and dependencies visible, which limits accidental metric drift. In B2B SaaS, that clarity often matters as much as the pipeline because stakeholder trust accumulates over time and resets quickly when the same metric returns different answers.
Define clear targets for accuracy, speed, and cost
Migration goals become defensible when accuracy tolerances, SLA targets, and cost baselines are expressed as measurable decision criteria rather than aspirations. Rollback triggers operate as operational stop conditions that limit prolonged ambiguity during parallel operation. Cost expectations also benefit from realism, since ELT does not inherently reduce spend if compute scaling, reprocessing, and dual-run overhead remain unbounded.
Define the future setup on AWS for simpler scaling
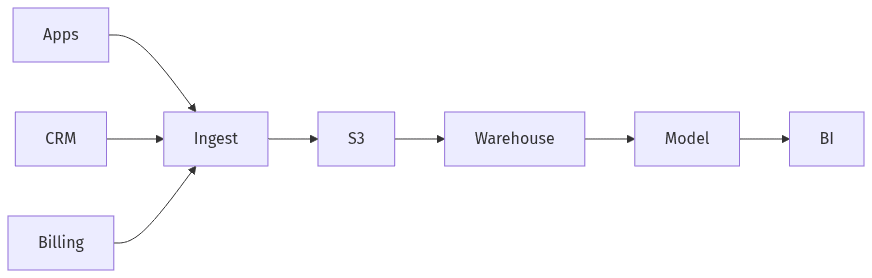 Simple AWS ELT flow from sources to dashboards
Simple AWS ELT flow from sources to dashboards
An ELT posture on AWS typically separates durable storage from elastic compute, with AWS S3 used for landing and historical persistence and a cloud data warehouse carrying analytical performance and governance. This shift relocates complexity: transformations become more visible, often more SQL-centric, and more tightly coupled to reporting semantics. For executives, the value tends to sit in clearer scaling characteristics and accountability boundaries, particularly when pipeline SLAs and backfill reliability have become brittle under rising event volume and expanding source diversity.
High-level data flow from source to reporting
A clear, high-level flow distinguishes raw ingestion, curated modeling, and consumption layers, with responsibilities aligned to each boundary. Separating storage and compute supports reprocessing and historical auditability, while increasing the need for governance around PII handling and access control. Reliability expectations often hinge on whether these layers make lateness, retries, and lineage observable rather than assumed.
Keep reporting logic consistent and easy to update
Reporting stability depends on transformation definitions that can evolve without hidden side effects. Incremental materializations reduce compute pressure and support fresher reporting as volumes rise, but they increase sensitivity to logic changes and late-arriving events. Executive confidence tends to improve when change tracking and metric versioning are treated as primary controls rather than downstream clean-up.
Move in phases with a safe cutover and easy rollback
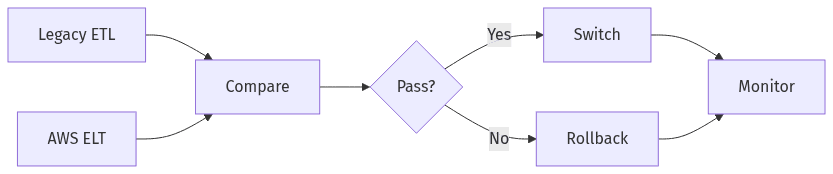 Phased migration with parallel run and rollback option
Phased migration with parallel run and rollback option
Incremental migration tends to outperform “big bang” replacements because it confines risk to a bounded slice of the business while maintaining continuity for critical reporting. In B2B SaaS, a costly failure mode is a broken KPI narrative that forces stakeholders to question historical trends. A phased approach also creates checkpoints for validating AWS cost and SLA assumptions, particularly during periods of unavoidable dual-running. Rollback readiness reads as operational discipline rather than pessimism, because it limits the duration of uncertainty.
Phased rollout plan by business area
Business-area slices often align to domains with clear ownership, such as finance KPIs versus product analytics, because accountability simplifies sign-off and dispute resolution. Timeboxed phases surface dependencies earlier, including shared dimensions, reuse of legacy transformations, and assumptions embedded in dashboards. The learning from early slices reduces downstream rework and protects core metrics from untested logic changes.
Parallel runs with clear switching and rollback criteria
Parallel runs function as an evidence period where legacy ETL outputs and ELT outputs coexist long enough to establish comparability. Common misconceptions appear here, including the assumption that dual-running is inexpensive or that differences can be dismissed without pre-set thresholds. Clear switching and rollback criteria shorten debate by anchoring decisions to agreed variance, freshness, and operational stability rather than subjective confidence.
Confirm accuracy and stability throughout the migration
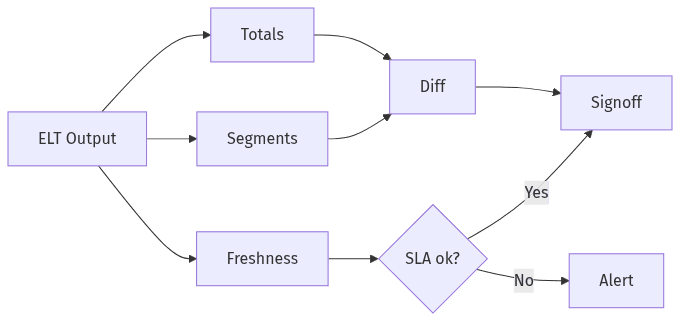 Ongoing checks for accuracy and freshness
Ongoing checks for accuracy and freshness
Validation is often the deciding factor in whether the migration preserves trust, because stakeholders interpret inconsistencies as governance breakdowns rather than technical nuance. Repeatable reconciliation creates an auditable comparability narrative across cutover, which matters for executive reporting and regulated contexts. Stability also includes timeliness: degraded SLAs can offset the perceived value of modernization even when infrastructure costs decrease. Observability, alerting, and explicit thresholds reduce firefighting by surfacing late data, retries, and duplication before dashboards become the detection mechanism.
Compare results during parallel runs
Comparisons extend beyond top-line totals into segmented checks across key dimensions, since offsets can cancel out at aggregate levels. Diff reports accelerate alignment by isolating where transformation logic diverges and which upstream sources drive variance. Executive stakeholders tend to care less about exact matches than about bounded, explained differences that preserve KPI integrity and historical comparability.
Ongoing checks for quality and timeliness
Ongoing quality checks focus on missingness, duplication, and out-of-order arrival, since these patterns commonly corrupt metrics in ELT pipelines. Timeliness monitoring maps directly to SLA credibility, especially once late events and retries become material at scale. Alerts tied to defined thresholds reduce silent failures that surface only during business reviews.
Prevent surprises in history reloads, costs, and ownership
Backfills and reprocessing often determine whether an ELT migration demonstrates reliability or exposes fragility. The hard problem is rarely executing a history reload; it is preserving idempotency so reruns do not inflate counts, overwrite trusted periods, or create irreconcilable KPI shifts. AWS cost scrutiny also makes the dual-running window and backfill compute a budget concern. Clear ownership, scope boundaries, and deliverables usually determine whether the effort remains controlled modernization or drifts into an open-ended platform rebuild.
Safe history reloads without duplicates
Idempotent load behavior and disciplined handling of watermarks shape whether reprocessing is audit-friendly or disruptive. Duplicate creation and destructive overwrites are common failure modes because they undermine confidence in historical reporting and complicate reconciliation. In many organizations, the ability to rerun with consistent outputs becomes a proxy for pipeline maturity and governance.
Control migration cost and clarify deliverables
Costs often spike during migration because parallel runs, reconciliation effort, and backfill compute overlap in time, even when the steady-state ELT model suggests lower spend. Clarity on roles and decision ownership limits delays, especially when disagreement arises over metric definitions, acceptable variance, or cutover readiness. Defined deliverables and handoff expectations support an operating model that balances pace with risk containment.


