Alex Fesak
CEO
SOC 2-Ready Data Warehouse Migration for B2B SaaS: Snowflake vs BigQuery vs Redshift (Cost Model, Security Controls, and Cutover Plan)
2026-05-23
Define what “SOC 2-ready” means for your migration
 SOC 2-ready scope and ownership across the analytics stack
SOC 2-ready scope and ownership across the analytics stack
In B2B SaaS, “SOC 2-ready” during a warehouse migration typically refers to a controls-and-evidence posture aligned to Security, Availability, and Confidentiality criteria, without suggesting that any vendor is “compliant” by default. Executive risk often concentrates around shared responsibility boundaries, defined system scope, and uptime expectations for revenue-critical analytics. A migration that appears technically straightforward can still fall short when controls coverage is unclear across the warehouse, pipelines, dbt, BI, and reverse ETL. Clear scope and accountable ownership usually determine whether the effort yields audit-ready narratives and evidence or a folder of ad hoc screenshots.
Set scope, boundaries, and ownership
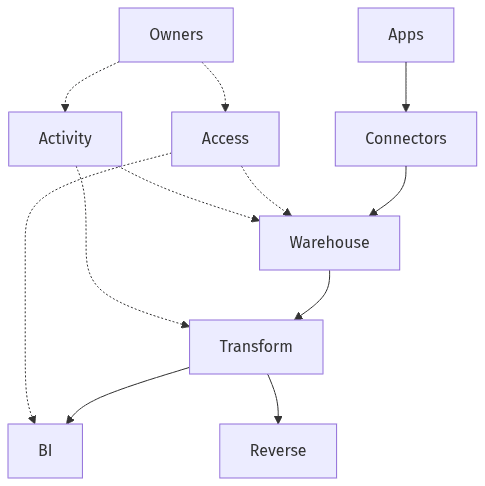
SOC 2 readiness typically depends on explicit boundaries: which data classes enter the warehouse, which environments are in scope, and which teams own access, changes, and monitoring. Shared responsibility tends to surface quickly across cloud providers, warehouse vendors, and internal operators. The difference shows up in control narratives and evidence repeatability, not platform feature lists.
List critical dependencies and risk areas
Warehouse migrations in SaaS often break where dependencies remain undocumented: BI dashboards, semantic definitions, operational reports, and downstream activations. Multi-tenant data isolation increases the blast radius of mistakes, since analytics access patterns frequently span teams and tools. Lineage visibility and named owners often become the deciding factor in recovery time expectations and audit defensibility.
Compare Snowflake, BigQuery, and Redshift for predictable costs
 Cost drivers and guardrails by platform
Cost drivers and guardrails by platform
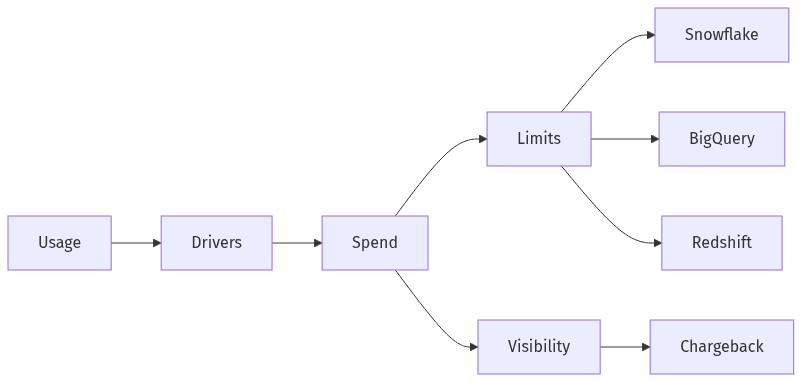
Cost predictability in analytics rarely comes from headline pricing; it comes from how each platform converts spiky usage into billable consumption and how cleanly that consumption can be attributed by team, product area, or tenant. Snowflake commonly centers costs on virtual warehouse compute and storage, BigQuery on on-demand query processing or reserved capacity, and Redshift on provisioned resources and workload management. For B2B SaaS with usage-based pricing and variable concurrency, cost risk more often hinges on guardrails, visibility, and workload isolation than on performance positioning.
Compare cost drivers at a high level
Cost surprises typically trace to query volume growth, concurrency, and multipliers such as transformation compute, storage retention, and data movement. Snowflake’s separation of compute from storage shifts attention to warehouse sizing, auto-suspend behavior, and query patterns. BigQuery’s model emphasizes query behavior and reservation posture. Redshift spend often concentrates in consistently provisioned capacity and governance of overlapping workloads.
Plan budget safeguards by platform
Predictable spend tends to correlate with platform-native guardrails and allocation models that match how SaaS organizations track consumption. Snowflake resource monitors and workload separation support attribution. BigQuery reservations and quotas influence spend stability. Redshift WLM and capacity planning reduce noisy-neighbor effects that distort per-team cost attribution. Multi-tenant analytics increases the value of clear isolation signals and transparent chargeback or showback.
Meet audit expectations for access and activity visibility
Auditors generally look for a coherent narrative across identity, access, logging, and review cadence rather than isolated configuration screenshots. During warehouse migrations, access control often fragments across the data warehouse, orchestrators, ELT connectors, dbt, BI, and reverse ETL, creating gaps in least-privilege enforcement and incomplete audit trails. SOC 2-focused scrutiny commonly lands on separation of production and non-production, clear distinction between human and service accounts, and evidence that access is reviewed and changes are governed. Activity visibility is most defensible when retention, ownership, and escalation expectations remain consistent across the stack.
Define who can access what
Least-privilege patterns in analytics typically separate analysts, engineers, and automated pipelines, with distinct roles for production versus development. Multi-tenant SaaS adds an additional boundary around tenant data isolation and limits on broad query privileges. Platform RBAC and IAM integration matter primarily for the resulting access review records and the ability to show consistent enforcement across tools.
Agree on activity records and retention
Audit expectations usually include sufficient activity history to support investigations, access reviews, and change traceability. Warehouse audit logs, query history, and pipeline and dbt job records often become the core evidence stream. Retention periods and clear ownership for periodic review frequently determine whether audit requests interrupt operations, especially when multiple tools generate overlapping but inconsistent logs.
Plan the migration to keep dashboards stable
 Parallel run, parity checks, and cutover decision
Parallel run, parity checks, and cutover decision
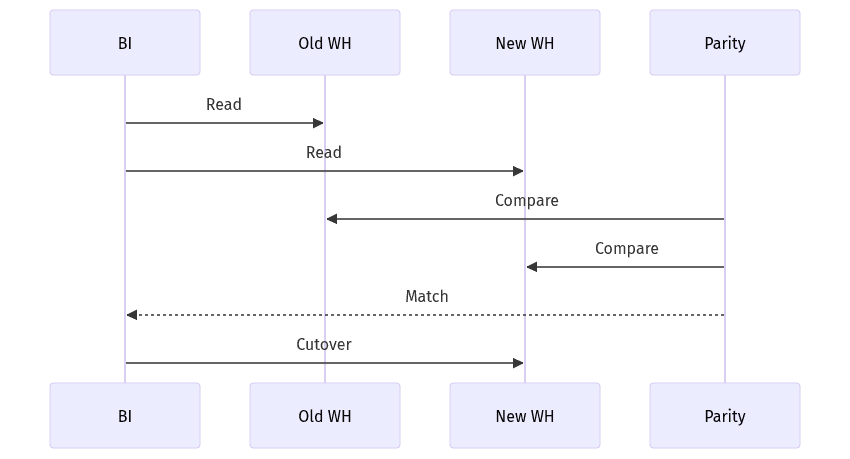
Dashboard stability often becomes the visible scorecard of a warehouse migration, independent of underlying progress. Breakage commonly stems from schema drift, renamed fields, semantic changes, or missing historical backfills rather than outright job failure. Lower-risk migrations in B2B SaaS typically favor incremental change with parallel visibility, since executive stakeholders treat analytics downtime as an availability incident even when core application uptime remains unaffected. Cutover risk also rises in multi-tenant reporting, where correctness and isolation expectations converge under customer scrutiny.
Use a phased cutover with decision gates
A phased cutover reduces risk by keeping the legacy warehouse as a reference point while confidence builds in the new environment. Decision gates function as explicit checkpoints for parity signoff, stakeholder alignment, and rollback readiness. Communication cadence often matters as much as technical readiness because dashboard changes propagate across teams quickly.
Confirm results match before switching over
Parity confidence rarely comes from row counts alone, which can mask logic differences and tenant-level discrepancies. Reconciliation queries and dbt tests often serve as the durable mechanism for detecting drift, particularly when scheduled and retained for evidence. Regular comparison of high-value metrics typically surfaces issues faster than broad, unfocused validation.
Turn the decision into a simple execution plan
Once a platform decision is made, migration success often depends on whether scope becomes a bounded set of deliverables that supports both SOC 2 evidence needs and ongoing analytics operations. Executive priorities typically converge around a small set of tracks: data modeling and transformations, access and logging controls, parity and monitoring, and downstream activation through BI and reverse ETL. The differentiator is often operating discipline after cutover, since SOC 2 readiness is sustained through repeatable reviews and retained records. A concise plan also supports commercial alignment when external data engineering and analytics partners are involved.
Build a focused backlog by priority
A migration backlog typically separates high-risk work from incremental enhancements, with early emphasis on data parity, permissions, logging, and BI stability. dbt models, tests, and exposures often provide a consistent structure for both correctness and evidence mapping. Reverse ETL and monitoring commonly appear as later tracks but remain tied to SOC 2 expectations through access control and activity records.
Define how the team runs it after cutover
Post-cutover operations often drive day-to-day compliance posture: access reviews, incident response expectations, and change control records across pipelines and analytics code. A clear RACI-style ownership story usually reduces audit friction and internal escalation loops. Reliability signals tend to come from consistent monitoring and retained job history rather than informal knowledge held by a small number of operators.