SOC 2–Aligned AWS DevOps for Healthtech SaaS: Reference Architecture for HIPAA-Ready CI/CD, Audit Evidence, and Zero-Downtime Releases
2026-04-27
Define an audit-ready DevOps baseline on AWS
In healthtech SaaS, an “audit-ready” DevOps baseline usually starts with shared scope around SOC 2 expectations and HIPAA safeguards, because tooling rarely compensates for unclear boundaries. Executive teams often see a gap between what engineering teams treat as “secure delivery” and what auditors look for: repeatable evidence across CI/CD, infrastructure as code, and production operations. AWS-native telemetry and access controls can support SOC 2 Trust Services Criteria—especially Security, Availability, and Confidentiality—while remaining HIPAA-aware, when the baseline treats CI/CD, IaC, logging, and identity as a single control surface rather than separate workstreams.
Controls that teams can follow day to day
Day-to-day control maturity typically presents as consistent expectations for change and access, expressed in operational terms: who can approve, who can deploy, what requires review, and what creates a durable record. SOC 2 alignment generally depends less on adding security tools and more on traceability, retention, and clear handling boundaries for PHI/ePHI. “HIPAA certified” language often introduces procurement friction because HIPAA is implemented through safeguards and shared responsibility, not product certification.
Practical tradeoffs for lean teams
Lean teams often face tension between segregation of duties and delivery velocity, particularly when the same individuals own infrastructure, pipelines, and production reliability. Auditors tend to accept pragmatic designs when exception paths and compensating controls are explicit and evidenced consistently. A small-team model often holds up when approvals, time-bounded access, and immutable audit trails reduce reliance on informal trust without turning delivery into a ticketing exercise.
Build a traceable delivery flow from code to production
 Traceable path from commit to production change record
Traceable path from commit to production change record
Traceable delivery on AWS becomes credible in audits when the path from code change to production outcome shows continuity across systems, not disconnected screenshots and one-off exports. SOC 2 change management review commonly centers on whether each release has documented review, approval, deployment visibility, and a defensible record of what changed. Terraform and GitOps can support that standard when plan/apply events, pipeline gates, and production changes read as one narrative across evidence sources such as CloudTrail, CI/CD logs, and repository history.
Clear separation between dev, stage, and production
Distinct environments tend to reduce operational confusion and audit exposure, particularly when PHI-handling boundaries are enforced consistently. In AWS, separation commonly aligns with segregated AWS accounts under AWS Organizations, reinforced by guardrails such as Service Control Policies and centralized identity. That structure often improves blast-radius containment and produces cleaner evidence because access and changes remain attributable to the correct environment context.
Change records that stand up in audits
Audit-ready change records typically show intent, review, approval, and outcome without relying on tribal knowledge. For infrastructure as code, a recurring gap is missing durable approvals around Terraform plan and apply, or an inability to link those artifacts to a specific deployment. Repository reviews, pipeline attestations, and AWS activity logs carry more weight when timestamps and identities align across systems.
Keep builds and releases safe for PHI
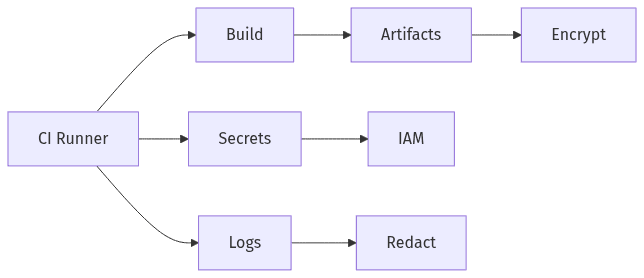 PHI-safe handling for secrets, logs, and artifacts
PHI-safe handling for secrets, logs, and artifacts
PHI exposure risk often concentrates in overlooked delivery surfaces: build logs, artifacts, debug traces, and temporary storage created during testing and deployment. Healthtech teams frequently find that CI/CD convenience features can conflict with HIPAA expectations when sensitive values appear in plaintext, when artifacts are stored without encryption, or when permissive access enables cross-environment leakage. On AWS, controls such as KMS-backed encryption, Secrets Manager, and tightly scoped IAM policies can reduce exposure, but their compliance relevance depends on whether evidence shows consistent use and whether outputs remain defensible under audit scrutiny.
Protect secrets and build outputs
Secret handling becomes an audit flashpoint when credentials or tokens appear in CI variables, build output, or deployment logs. AWS services such as Secrets Manager and Parameter Store, combined with KMS encryption and least-privilege IAM, commonly support a defensible confidentiality posture. Artifact encryption and controlled retention also matter because build outputs often persist longer than assumed and can become an untracked PHI-adjacent exposure surface.
Keep logs and test data clean
Log and test-data hygiene often determines whether a delivery system stays HIPAA-aware operationally, not only on paper. Debug logging and “realistic” fixtures can introduce PHI into locations that were never designed for regulated retention and access controls. Auditors often look for evidence that logs and test materials avoid sensitive content, and that centralized logging retains only what is necessary with accountable access.
Automate audit evidence and access accountability
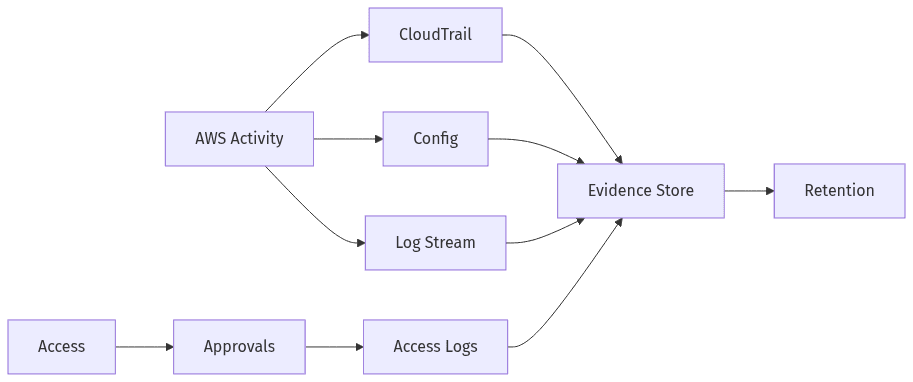 Continuous evidence and accountable access across AWS
Continuous evidence and accountable access across AWS
SOC 2 efforts often falter during audits when evidence collection turns into a late manual scramble across AWS, CI/CD, and IaC tooling. Continuous evidence reduces audit friction when signals are durable, centralized, and retained under consistent policy. AWS-native sources such as CloudTrail, AWS Config, and CloudWatch Logs commonly provide high-value records, but a recurring misconception is that CloudTrail alone closes the evidence gap. Executive confidence typically improves when evidence includes immutability controls, explicit retention decisions, and end-to-end traceability for routine changes and elevated access events.
Always-on audit trails and retention
Always-on audit trails typically combine event history with configuration history, showing “what changed” alongside “who did it.” CloudTrail, AWS Config, and centralized log aggregation often form the evidence spine, while S3 Object Lock and WORM-style retention improve confidence in immutability. Retention periods usually reflect internal policy and customer expectations, and auditors often test for coverage gaps across accounts, regions, and critical services.
Lean access boundaries and emergency access
Access accountability in lean organizations often depends on tight boundaries for routine access and highly visible controls for exceptions. Least-privilege IAM, role-based access through IAM Identity Center, and organization-level guardrails commonly reduce exposure from broad permissions. Emergency or “break-glass” access is consistently audit-sensitive; time-bounded elevation with explicit approvals and comprehensive logging is generally more defensible than persistent admin entitlements.
Release with minimal downtime and clear rollback paths
Downtime sensitivity in healthtech SaaS often collides with compliance expectations when release speed outpaces change visibility or approval traceability. On AWS, deployment patterns such as blue/green and canary are often tied to availability, but their compliance relevance depends on whether decision history remains intact and whether post-release outcomes are observable. SOC 2-aligned release governance typically treats controlled rollout and controlled rollback as one evidence story, particularly when regulated workloads and PHI-adjacent services increase the impact of instability.
Choose a low-risk release approach
Low-risk release approaches typically share two properties: limited blast radius and measurable health signals. Blue/green and canary methods commonly fit that profile on AWS for ECS, EKS, Lambda, and other managed compute options, while auditability depends on linkage to approvals and deployment records. Automated health checks often become the boundary between controlled change and unmanaged risk, especially under availability commitments.
Tie releases to response and recovery
Release activity is easier to defend when incident response and recovery decisions appear in the same operational narrative as deployments. SOC 2 Availability expectations often surface as questions about restoration timing and how changes are governed during instability. Change windows and rollback decisions tend to be evaluated less as ceremony and more as evidence of deliberate risk management, particularly when regulated customers expect reliability with audit-grade traceability.


