Event-Driven Microservices on AWS for B2B SaaS: A Reference Architecture for Billing, Entitlements, and Usage-Based Pricing
2026-05-03
Clarify billing, entitlements, and metering responsibilities
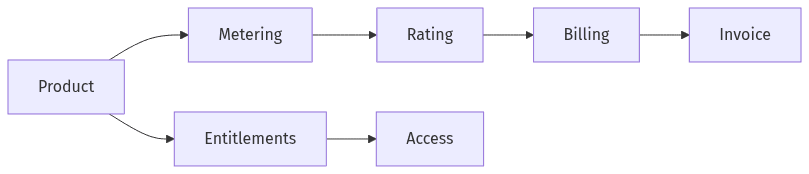 Clear domain boundaries across monetization services
Clear domain boundaries across monetization services
Event-driven microservices on AWS for B2B SaaS tend to succeed or fail on domain boundaries, particularly when subscriptions and usage-based pricing coexist. Billing typically operates as the financial system of record, carrying invoice state, adjustments, and auditability expectations aligned to SOX-style controls. Entitlements usually represent customer-facing access and plan interpretation, and they often change at product cadence. Metering and rating commonly sit between them, translating usage events into billable quantities and pricing dimensions. When responsibilities blur, asynchronous updates introduce state drift, release coordination increases, and monetization behavior becomes harder to evidence during incidents and audits.
Set ownership and boundaries
Well-defined bounded contexts reduce overlapping logic that later becomes “who owns the truth” disagreements. Billing generally owns financial ledgers, invoicing, credits, and dunning outcomes; entitlements owns feature access and plan rules; metering owns usage capture and aggregation semantics. Shared ownership typically shows up as duplicated state across services, followed by reconciliation overhead that grows with product surface area and regional expansion.
Agree on key business events
A stable event taxonomy functions as a shared vocabulary across product, engineering, and operations. Events such as UsageRecorded, EntitlementGranted, PlanChanged, and InvoiceIssued often anchor cross-service understanding, with careful attention to the implied business sequence. Consistent naming and semantics matter because downstream systems commonly treat these events as contractual facts, not transient integration signals.
Choose an AWS messaging approach that fits your needs
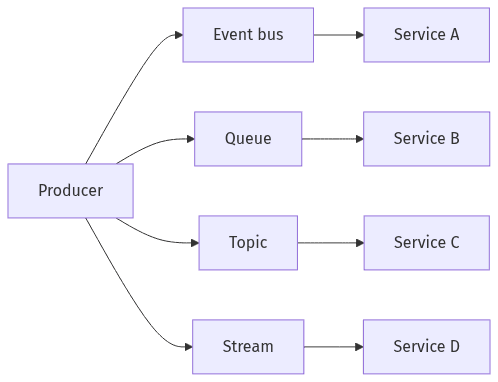 Common AWS messaging shapes for service-to-service updates
Common AWS messaging shapes for service-to-service updates
AWS-native messaging choices shape correctness properties as much as throughput and cost. EventBridge often fits broad routing and integration, particularly where multiple consumers evolve independently and replay has operational value. SQS and SNS commonly appear where delivery guarantees and isolation are prioritized, with FIFO behavior used selectively when ordering is part of the business contract rather than a performance preference. Kinesis Data Streams frequently aligns with high-volume usage pipelines where partition-level sequencing supports metering semantics. Across these options, at-least-once delivery is a baseline operating condition, not an edge case.
Connect services reliably
Loose coupling usually comes from explicit routing and narrowly scoped subscriptions, not elaborate choreography. Event buses and queues support different integration shapes: broad fan-out versus targeted delivery, longer retention versus short-lived transport, and replay versus redelivery. In monetization domains, reliability expectations typically push designs toward replay-safe consumption and observable delivery states.
Keep each service independent
Service independence tends to correlate with per-service persistence and explicit contracts rather than shared schemas. DynamoDB, Aurora, and other AWS data stores commonly sit behind domain boundaries, with events serving as the interoperability layer. Shared persistence can reduce early coordination costs, but it often turns deployment autonomy into a coordinated release train—an outcome that conflicts with microservices expectations in billing-critical environments.
Avoid billing mistakes with safe processing and recovery
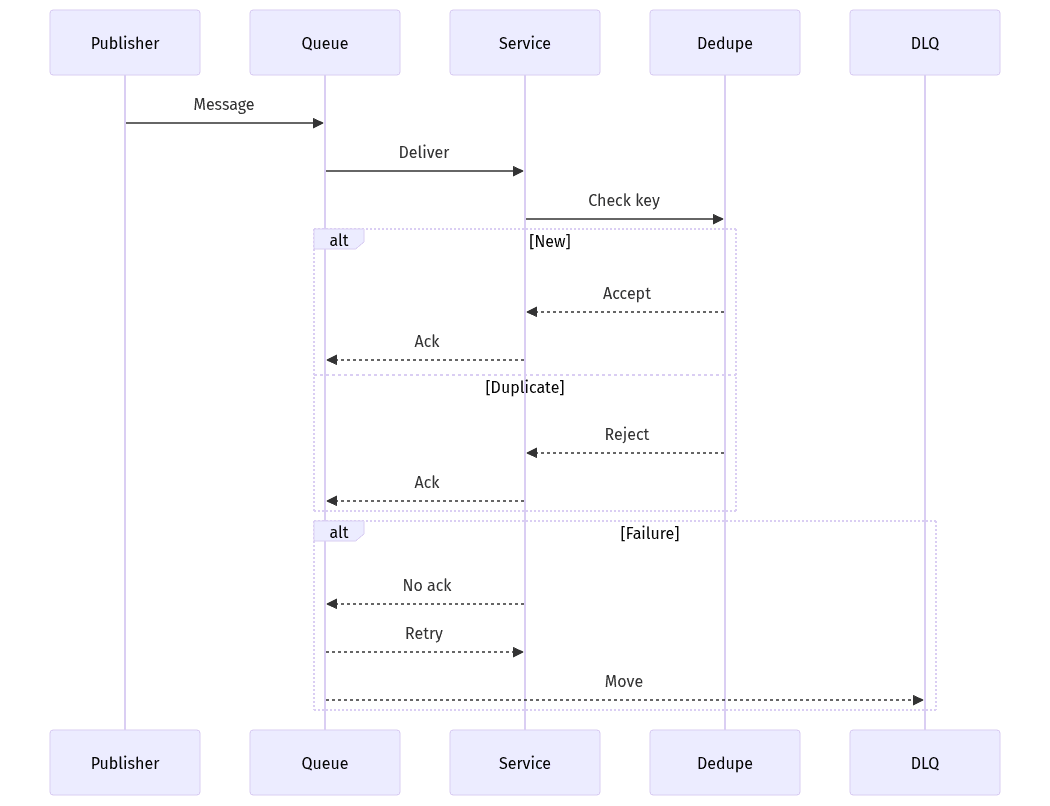 Repeat-safe handling with retries and dead-letter routing
Repeat-safe handling with retries and dead-letter routing
Billing incidents in event-driven systems rarely come from missing messages alone; duplicates, retries, and partial failures are usually the larger risk surface. Exactly-once assumptions tend to fail under operational conditions such as consumer timeouts, visibility-window expirations, and redeliveries. Repeat-safe processing becomes a prerequisite for preventing double charges, duplicate entitlement grants, and inflated usage. Recovery readiness also shapes risk posture: poison messages, DLQs, and replay paths affect not only uptime, but also the ability to deliver deterministic customer outcomes and defensible audit trails after an incident.
Make processing repeat-safe
Idempotency keys and deduplication records commonly serve as the practical alternative to exactly-once guarantees. Repeat-safe handling treats replays and retries as expected inputs, which is particularly relevant for invoices, credits, and usage-to-charge transformations. The same discipline applies to entitlements, where duplicate grants can translate into revenue leakage or contractual exposure.
Plan for failures and reprocessing
Operational clarity often appears as explicit handling of DLQs, poison messages, and replay windows, paired with observability that supports traceability across services. Archive and replay capabilities in AWS services can change incident response mechanics, but they also introduce governance constraints around retention, GDPR boundaries, and audit expectations for revenue-impacting event histories.
Keep services consistent without tight coupling
Eventual consistency changes how “correctness” is evaluated across billing, entitlements, and metering. Within each domain, internal state can remain strongly consistent, while cross-domain outcomes converge through events, compensation, and reconciliation. This separation allows independent releases, but it also normalizes time gaps and partial views as operating conditions. Transaction boundaries become a design constraint: cross-service ACID transactions typically give way to patterns such as transactional outbox/inbox and saga-style compensation, particularly when each service maintains its own database and failure isolation is non-negotiable.
Publish changes safely
The transactional outbox pattern commonly bridges local commits and downstream messaging, limiting gaps between stored state and emitted events when failures occur. Inbox-style deduplication on the consumer side complements this by turning at-least-once delivery into deterministic state transitions. These patterns tend to carry the most weight in monetization paths, where ambiguous dual-updates translate into financial defects or access-control errors.
Handle corrections cleanly
Corrections usually appear as first-class financial artifacts—adjustments, credit notes, or compensating entries—rather than silent rewrites. An audit-minded posture typically favors immutable events and ledger-like billing records, supporting reconciliation when metering logic changes, pricing rules evolve, or late-arriving usage affects prior outcomes. This limits the blast radius of defects while preserving explainability for customers and auditors.
Support growth with sequencing and gradual migration
Scaling usage-based pricing introduces two recurring challenges: sequencing semantics and migration safety. Ordering guarantees are usually scoped rather than global, which conflicts with assumptions about strictly ordered streams across regions and services. Business correctness often depends on per-tenant or per-account sequencing for specific event types, not blanket ordering across all traffic. Migration from a monolith adds another risk layer because parallel implementations can create drift across billing and entitlements. Gradual change often becomes the practical control that protects revenue integrity while limiting release coordination.
Keep important sequences intact
Ordering constraints commonly concentrate around tenant-scoped usage sequences, invoice lifecycle transitions, and plan-change effects on rating. FIFO queues and stream partitioning can preserve scoped order, but only within defined keys, not across the system. Multi-region usage pipelines further complicate aggregation windows due to latency and clock skew, increasing reliance on reconciliation rather than assumed perfect sequencing.
Evolve safely during migration
Phased migration patterns often reduce monetization risk by limiting the active surface area of change while keeping rollback options viable. Parallel run periods tend to surface schema evolution pressure, contract stability constraints, and drift-detection needs earlier than a single cutover. Acceptance criteria often center on reconciliation accuracy, replay safety, and controlled error budgets, rather than only functional parity with the monolith.