Data Contract–Driven Integrations for B2B SaaS: How to Prevent API Breakages During Microservice Extraction (With SLA Monitoring and Rollback Plans)
2026-05-06
Define what must stay stable for partners during extraction
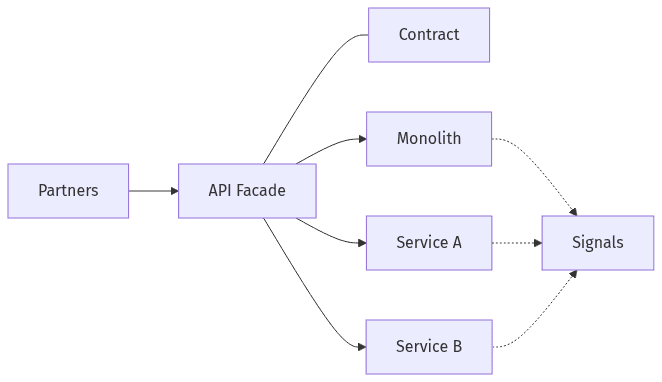 Partner stability boundary during service extraction
Partner stability boundary during service extraction
Microservice extraction typically changes where logic runs, not what external partners expect to receive. The least disruptive migrations treat partner integrations as a stability boundary, with data contracts capturing behaviors that cannot drift as responsibilities move across services. That boundary usually covers request/response schemas, webhook and event payloads, error semantics, idempotency expectations, and latency and throughput characteristics that downstream automations rely on. When stability is left implicit, teams often find that “equivalent” refactors shift edge behavior—triggering escalations, partner churn, and credibility loss that persists beyond the cutover.
Map partner-facing APIs and expectations
Partner-facing surfaces often extend beyond nominal “public endpoints” to include webhooks, asynchronous events, pagination behavior, filtering edge cases, and tolerated latency. Integration fragility commonly clusters around undocumented assumptions: fields treated as non-null, loosely defined enums, error codes reused for different conditions, and timing expectations embedded in partner automations. Data contracts make those implicit assumptions explicit, so they remain stable while internal boundaries move.
Assign clear ownership for changes
Decentralized service ownership can blur accountability for partner outcomes, especially when one external API spans multiple internal services. Ownership often works best when anchored to the contract: who approves partner-impacting changes, who arbitrates compatibility disputes, and who maintains change-management evidence. Cross-team contract review norms reduce “local” optimizations that create external regressions.
Evolve APIs safely with clear versioning expectations
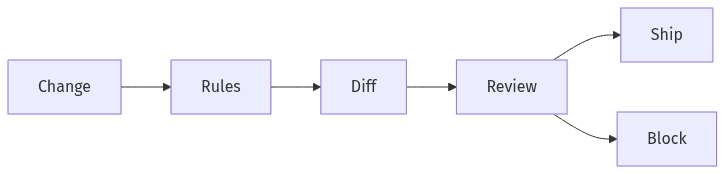 Change gates to reduce partner-breaking updates
Change gates to reduce partner-breaking updates
Versioning is often treated as the primary safety mechanism during migrations, yet semantic versioning alone rarely prevents breakage when external consumers cannot coordinate upgrades. Reliability depends more on compatibility rules than on version labels: which changes are additive, which require deprecation windows, and which are unacceptable without parallel support. During monolith decomposition, contract-first practices also limit version proliferation by keeping the public surface stable while internal services evolve behind it, typically through governance rather than new URLs.
Define what changes are safe versus breaking
Breaking changes generally include removals, type changes, stricter validation, altered default behavior, and shifts in error semantics. Additions that appear “safe” can still break consumers that enforce strict schema validation or assume enum completeness. A clear taxonomy defines backward compatibility under typical partner constraints, not under idealized client behavior.
Catch breaking changes before release
Pre-release compatibility checks move discovery from production incidents to earlier review points. OpenAPI and AsyncAPI artifacts support automated schema diffing, while contract registries and governance controls support traceability for audit and change evidence. The practical value is early visibility into partner impact, particularly when multiple teams ship independently during an extraction program.
Validate partner impact before production releases
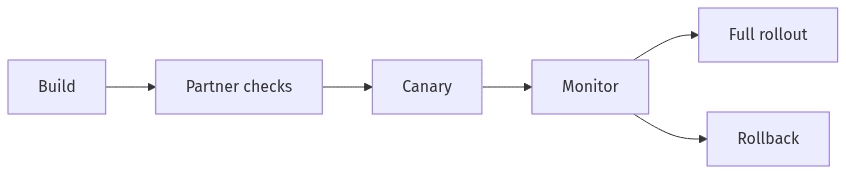 Canary plus rollback limits partner impact
Canary plus rollback limits partner impact
External integrations behave like a long tail: a small number of high-volume partners and many low-volume or unknown consumers. That distribution limits confidence in internal test suites alone, because provider-correct behavior can still violate consumer expectations. Consumer-driven contracts and partner-like verification provide a proxy for real consumption, while progressive delivery techniques reduce the cost of learning. During extraction, the combination often functions as a control plane for integration risk, limiting surprises and protecting revenue-critical workflows.
Use partner-like checks alongside builds
Consumer-driven contract testing emphasizes published expectations of consumption rather than provider intent. For partner APIs, that emphasis matters because unknown consumers and long-lived integrations rarely align tightly to documentation changes. Verification signals that resemble partner usage—request patterns, header requirements, error handling behavior, and payload tolerance—often surface compatibility gaps earlier than provider-centric tests.
Release gradually with fast rollback options
Canary releases limit blast radius when an extracted service or facade changes partner-visible behavior. Rollback planning and feature-flag control matter because integration incidents often require reversibility under time pressure, while some migrations introduce state transitions that are difficult to undo. Executive risk posture frequently depends on whether reversibility exists for partner-impacting changes, not solely on deployment cadence.
Monitor partner experience end-to-end
Service health and partner experience often diverge during microservice transitions. Internal metrics may remain steady while partners see higher tail latency, authentication edge-case failures, webhook delivery gaps, or elevated error rates on specific methods. Partner-oriented SLA/SLO monitoring narrows that gap by observing outcomes aligned to integration value: availability of key endpoints, delivery success for events, correctness signals, and time-to-first-byte or end-to-end latency. The same framing supports error budgets and clearer stakeholder communication when reliability tradeoffs arise.
Track service levels that matter to partners
Partner dashboards typically segment by API product, endpoint group, and consumer identity or tier, rather than by microservice. Availability alone rarely captures integration harm; correctness indicators and latency distributions usually correlate more directly with tickets and churn. Observability coverage across logs, traces, and metrics becomes a prerequisite for credible SLA reporting as boundaries shift.
Prepare response plans for integration incidents
Integration incidents can cascade into contractual and reputational exposure, particularly when partners automate critical workflows. Response maturity is reflected in alert signal quality, triage clarity, and time-to-restore, with MTTR often more consequential than root-cause depth in the first hour. Audit logs, change evidence, and a clear incident timeline also support regulated environments and partner trust.
Check readiness and risk before starting extraction
Extraction readiness rarely hinges on technical feasibility alone; integration topology, consumer coordination constraints, and change frequency often drive risk and cost. Programs that start without a grounded view of contract stability, observability gaps, and rollback limits commonly encounter integration churn that consumes the same engineering capacity intended for migration. A readiness view that ties partner impact to delivery throughput supports executive planning, including sequencing decisions, budget expectations, and external communications connected to reliability commitments and uptime obligations.
Score risk and team capacity
Risk typically increases with unknown consumers, high change velocity, weak schema governance, and limited tracing across service boundaries. Capacity constraints show up in integration support load, on-call fatigue, and cross-team coordination overhead. A structured risk-and-capacity view usually yields a more defensible migration forecast than architecture diagrams alone.
Plan a partner-friendly rollout sequence
Sequencing choices often separate low-risk extraction milestones from partner-visible breakpoints. Partner-friendly sequencing generally preserves the external contract while internal boundaries shift, with deprecations managed as a product concern rather than an engineering footnote. The commercial effect is fewer escalations and lower churn risk, supporting migration momentum and more credible narratives with customers and partners.