RAG vs Fine-Tuning for Fintech Customer Support: A Cost, Compliance, and Time-to-Value Decision Framework
2026-04-28
Start with risk and regulatory expectations
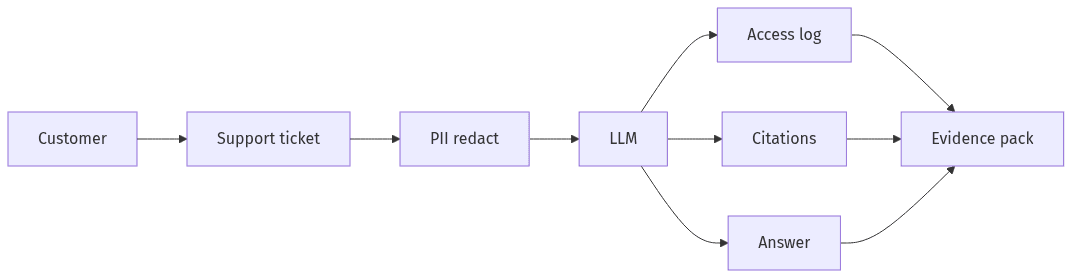 Support answer evidence and data boundaries
Support answer evidence and data boundaries
In fintech customer support, the RAG vs fine-tuning decision rarely starts with model capability and more often starts with risk posture. Customer communications routinely involve regulated data, operational SLAs, and supervisory expectations around recordkeeping and consistency. Options that appear interchangeable in a demo can diverge quickly under audits, vendor risk reviews, and privacy assessments. A compliance-forward view clarifies what evidence must exist after each response, where data can travel, and what needs to be retained. Those constraints typically narrow the design space before cost and time-to-value comparisons become decision drivers.
Audit readiness basics
Audit readiness in LLM-based support usually centers on traceability: which sources informed an answer, which policies constrained it, and which logs support reconstruction. Regulators and internal control functions typically look for an evidence pack that ties outputs to approved knowledge, captures access and change history, and supports after-the-fact review. Risk often concentrates in nondeterministic behavior, fast-moving knowledge bases, and incomplete records of what context the model received.
Privacy and data handling essentials
Privacy constraints often determine feasibility because support tickets blend identity data, account context, and free-text disclosures. GDPR and the GLBA Safeguards Rule raise expectations around minimization, retention, access controls, and vendor oversight. Data residency obligations and contractual limits on provider data use influence whether sensitive content can leave a region or controlled environment. Redaction and DLP controls also introduce accuracy tradeoffs when key identifiers affect intent classification and retrieval precision.
Compare RAG and fine-tuning for support outcomes
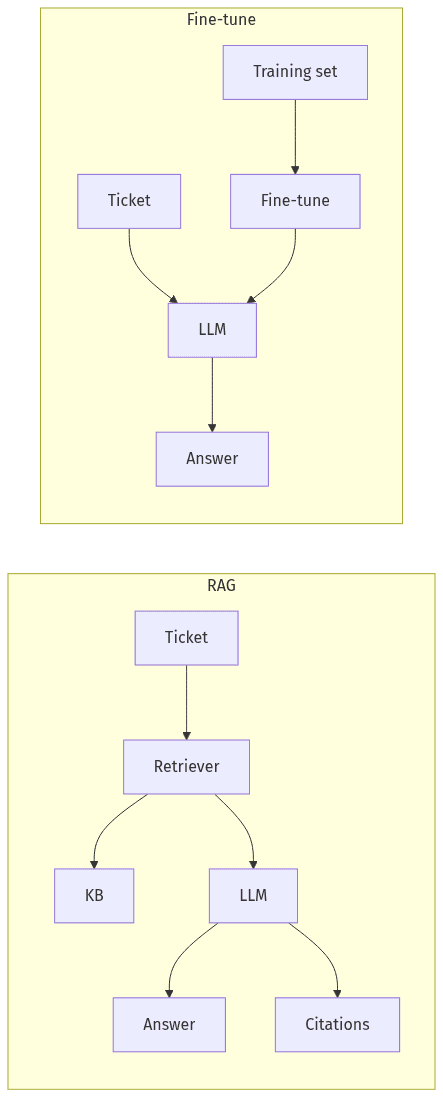 RAG and fine-tune patterns for support
RAG and fine-tune patterns for support
RAG and fine-tuning can produce similar surface-level support responses, but they differ in how correctness, change control, and governance show up in production. RAG typically ties answers to retrievable, approved sources, which maps to policy-driven support and frequent content updates. Fine-tuning typically encodes behavior in model weights, which can tighten consistency for narrow intents but complicates change control and evidence collection. Executive evaluation often converges on three dimensions: reliability under policy change, audit defensibility, and the ongoing cost of maintenance.
Where RAG is a better fit
RAG often fits fintech support where answers must remain bound to current, approved knowledge such as policies, product terms, and procedural guidance. Freshness matters because content churn is routine, and retrieval supports updates without retraining cycles. Audit narratives can benefit from citations and source traceability, provided knowledge management is controlled and versioned. The operational risk shifts toward retrieval quality, knowledge base drift, and coverage gaps.
Where fine-tuning is a better fit
Fine-tuning often fits fintech support where the scope is narrow, requests are repeatable, and response-style consistency has operational value. Stable intents such as templated explanations or structured classifications can benefit from learned patterns. Risk discussions commonly focus on brittleness under policy change, limited explainability for why specific phrasing appeared, and overfitting to historical tickets. Governance overhead often concentrates in refresh cycles and regression scrutiny after updates.
Reduce bad answers with guardrails and escalation
 Guardrails and escalation to reduce risky answers
Guardrails and escalation to reduce risky answers
In regulated customer support, the consequential question is not whether hallucinations occur, but how often they reach customer-facing channels and whether controls make failures reviewable and defensible. Both RAG and fine-tuning require explicit safety boundaries because support content can drift into financial advice, identity verification, disputes handling, or sensitive account actions. In mature operations, unsafe or ambiguous prompts are treated as normal operating conditions rather than edge cases. The customer-visible outcome is reduced harm; the operational requirement is a control narrative that stands up to audit and incident review.
Grounding and citation expectations
Grounding standards typically separate acceptable, knowledge-backed answers from speculative language. Citation expectations also shape governance because links to controlled sources support quality review, agent oversight, and audit inquiries. The claim that RAG is inherently auditable often overlooks the dependence on retrieval integrity and content governance. A fail-closed posture becomes important when sources are missing, conflicting, or outdated, particularly for policy and disputes topics.
Escalation rules and review checks
Escalation and review controls often reduce risk more than additional model sophistication. Human handoffs protect customers when confidence is low, content is disallowed, or the ticket touches regulated actions. Quality review typically includes spot checks and a curated “golden ticket” set to surface drift over time. The executive signal is a measurable balance between automation rates, safe deflection, and containment of high-impact failures.
Understand ongoing costs and operations
Total cost of ownership in LLM support extends beyond initial integration and includes governance, evaluation, and ongoing change management. In fintech, cost narratives often break down when audit and privacy controls introduce logging, retention, access reviews, and vendor oversight. Operational burden also increases as policies, FAQs, and product terms change, turning support knowledge into a moving target. RAG and fine-tuning shift costs into different buckets: one toward content and retrieval maintenance, the other toward model updates and regression exposure. Executive planning typically emphasizes sustainability under policy churn and control scrutiny.
Ongoing costs to watch with RAG
RAG costs often cluster around content operations and performance stability: indexing, retrieval quality, and knowledge base governance. Drift emerges when documents change, duplicates accumulate, or conflicting versions remain accessible. Evaluation effort matters because citation coverage and groundedness need consistent measurement. Security and privacy overhead can increase with additional components touching ticketing systems, vector stores, and knowledge repositories, particularly under strict access logging and residency constraints.
Ongoing costs to watch with fine-tuning
Fine-tuning costs often concentrate in refresh cycles, dataset governance, and monitoring for behavioral regressions after policy updates. Training data constraints become more costly in regulated environments because sensitive ticket content requires tight access controls and retention discipline. Quality management becomes a recurring line item since narrow gains can trade off against generalization. Vendor and model portability considerations frequently enter the TCO conversation when fine-tuning artifacts tie performance to a specific provider or model family.
Validate value quickly with a focused proof
A short proof of value often functions as a governance exercise as much as a product experiment. In regulated fintech, executives typically look for evidence that tier‑1 ticket quality improves, unsafe content remains contained, and audit artifacts are available without adding material operational load. Time-to-value becomes credible when the trial yields measurable outcomes rather than demo performance. The most decision-relevant outputs usually relate to accuracy on real ticket language, privacy controls around PII, citation behavior, and operational impact on agents. Vendor-neutrality can matter under procurement and vendor risk scrutiny.
Success metrics and scope
PoV scope usually centers on a defined tier‑1 ticket set with repeatable issues and controlled knowledge sources. Metrics commonly include grounded-answer accuracy, citation coverage, escalation rate, and latency, paired with structured human review outcomes. Hallucination monitoring tends to rely on explicit error taxonomies rather than generic “quality” scores. Risk stakeholders often look for minimization evidence related to sensitive data exposure and for a defensible approach to disallowed content.
Evidence outputs for decision-makers
Decision-makers typically require artifacts that translate model behavior into approvable evidence: audit logs, citation reports, retention and residency attestations, and evaluation summaries showing performance against a stable test set. Procurement and vendor risk teams often expect clear descriptions of data flows, what is stored, and how long records persist. A regulator-ready narrative usually depends on traceability, defined reproducibility boundaries, and documented control points rather than broad claims of compliance.